
Needle in a haystack: How we found and solved a memory leak in our integration framework


Table of contents
- Introduction
- The Symptoms: When Memory Just Won’t Free Itself
- Phase 1: Reproducing the Issue in the Right Environment
- Phase 2: Memory Profiling and the Search for Fragmentation
- Phase 3: Isolating Code with a Binary Search Strategy
- Phase 4: The Surprising Culprit — Duplicated Route Registration
- The Fix: Ensuring Single Route Registration
- Lessons Learned: Debugging the Hard Way
- Conclusion
- Additional Resources
Introduction
Memory leaks are a source of frustration for software engineers. They hide in the depths of complex codebases, manifesting subtly but growing steadily until they disrupt the entire system.
This was precisely the situation we faced in our Python-based, open-source Ocean framework. Ocean powers data integrations in our internal developer platform, Port, that fetch, transform, and sync data from various sources into a modeled catalog. It consists of two key components: the core, which handles integration management, and the integrations themselves, which handle specific data sources.
In this blog, we'll discuss a memory leak discovered in some of our integrations running in production. This issue caused resource exhaustion over time and turned into a challenge, requiring creativity, trial and error, and out-of-the-box thinking to resolve. The challenge was to locate and resolve the issue without causing disruptions for our users.
We’re going to dive deep and take you through our journey of investigating the leak—from hypothesizing and testing potential causes to the unexpected discovery that saved the day.
The Symptoms: When Memory Just Won’t Free Itself
Users reported escalating memory usage during resyncs—a process in which Ocean integrations fetch large volumes of data from external sources to ensure synchronization with the latest updates in the portal. For example, in the case of Jira, a resync might involve retrieving tens of thousands of issue records in a single operation. This critical operation is designed to handle large-scale data efficiently, but the memory usage during these tasks was increasing unexpectedly and without bounds.
The primary symptom: the resident set size (RSS) memory (held in RAM and managed by the OS) was increasing endlessly, even though Python’s heap memory usage appeared stable. Over time, this behavior can exhaust available system memory, degrade performance, and ultimately cause the application to crash or force the OS to terminate the process.
For long-running applications like Ocean, ensuring stable and predictable memory usage is critical to maintaining reliability in production environments. We needed to figure out why this memory wasn’t being released back to the system.
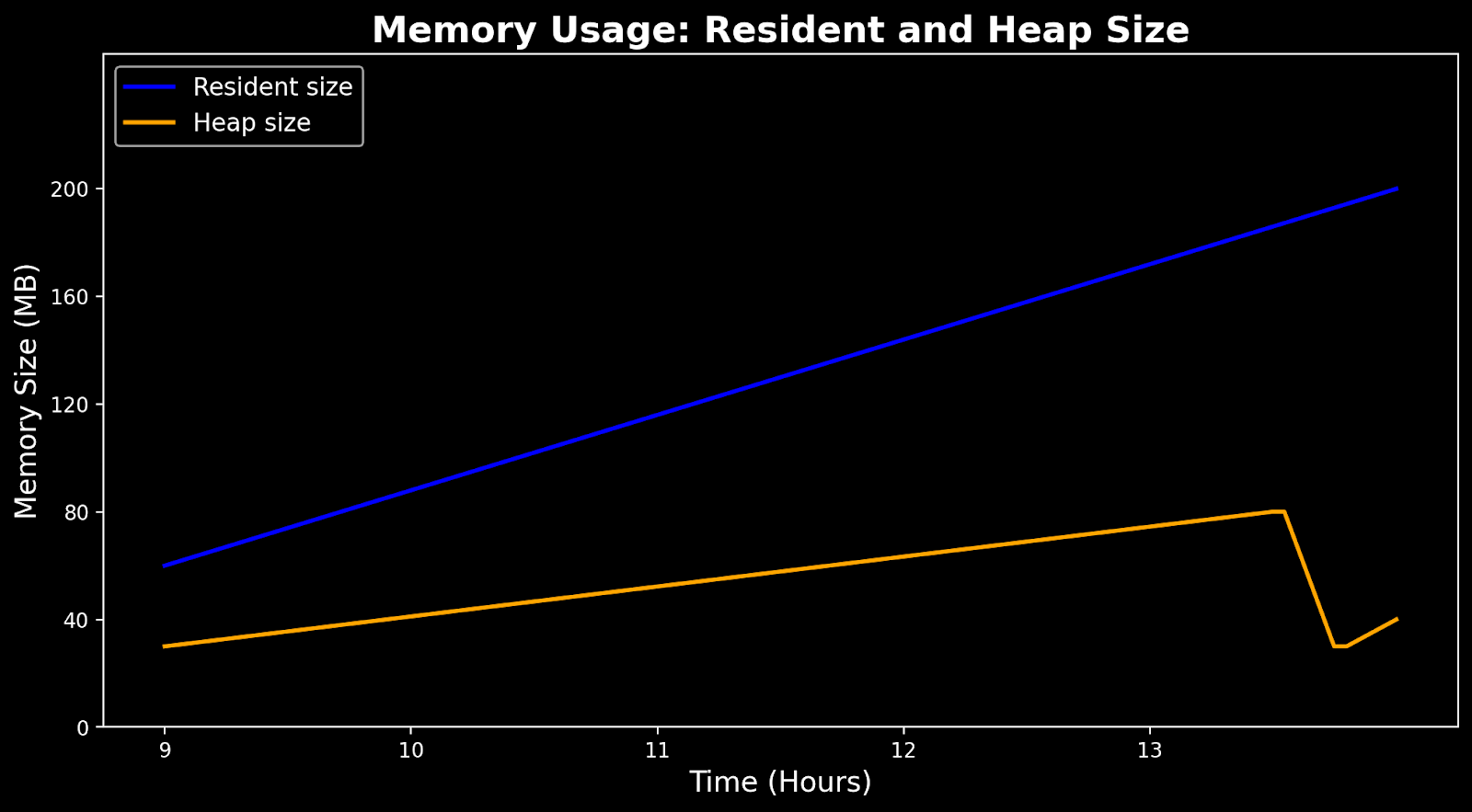
Memory usage - resident vs. heap
Phase 1: Reproducing the Issue in the Right Environment
Reproducing the memory leak in a controlled environment proved to be a major challenge. Locally, even with extensive testing, we couldn’t replicate the issue that our customers were experiencing. Memory usage remained stable in our development setups, and the pattern of memory growth just wasn’t apparent.
The breakthrough came when we realized that the scale of the data and infrastructure mattered. The issue only became noticeable when we created a significant load—specifically, 30,000 Jira issues—and deployed it on a Kubernetes cluster using our Helm chart, mimicking our customers' production environment.
This highlights why the issue was difficult to detect, even by our production customers. The leak required an exceptionally large load to manifest. In most common cases, the integration would leak at such a slow pace that the impact was barely noticeable and didn’t immediately affect performance. As a result, the problem could persist undetected for extended periods, only becoming critical in high-demand environments.
Phase 2: Memory Profiling and the Search for Fragmentation
We turned to memory profiling tools like Memray, which gave us granular visibility into Python object allocations, and helped to identify patterns of memory usage that might point to leaks or inefficient allocations.
Alongside profiling, we explored alternative memory allocators like jemalloc and tcmalloc. These allocators are often used to address issues such as memory fragmentation, a condition where free memory becomes scattered into non-contiguous blocks, making it difficult for the operating system to allocate large chunks of memory when needed.
We configured jemalloc with aggressive memory release settings using the MALLOC_CONF environment variable, with the following settings:
narenas:1: By default, jemalloc uses multiple arenas (memory pools) to reduce contention in multi-threaded applications. However, this can lead to fragmentation, especially in low-concurrency environments. Reducing the number of arenas to 1 forces all allocations to use the same arena, minimizing fragmentation at the cost of potential performance degradation in highly concurrent workloads.
tcache:false: The thread-local cache stores recently freed memory chunks to speed up future allocations. Disabling it ensures that freed memory is immediately returned to the central allocator for reuse or release.
dirty_decay_ms:0 and muzzy_decay_ms:0: These control how quickly jemalloc returns unused memory pages to the operating system. Setting these decay times to 0 forces immediate release of these pages, ensuring that jemalloc doesn’t hold onto unused memory longer than necessary.
In contrast to naive memory release strategies, which prioritize performance by retaining memory for quick reuse, these aggressive settings helped us verify whether the issue stemmed from jemalloc's handling of fragmentation or delayed memory release. While this approach improved memory usage patterns, it revealed that the root cause of the leak was unrelated to fragmentation or allocator behavior, allowing us to focus on other parts of the system.
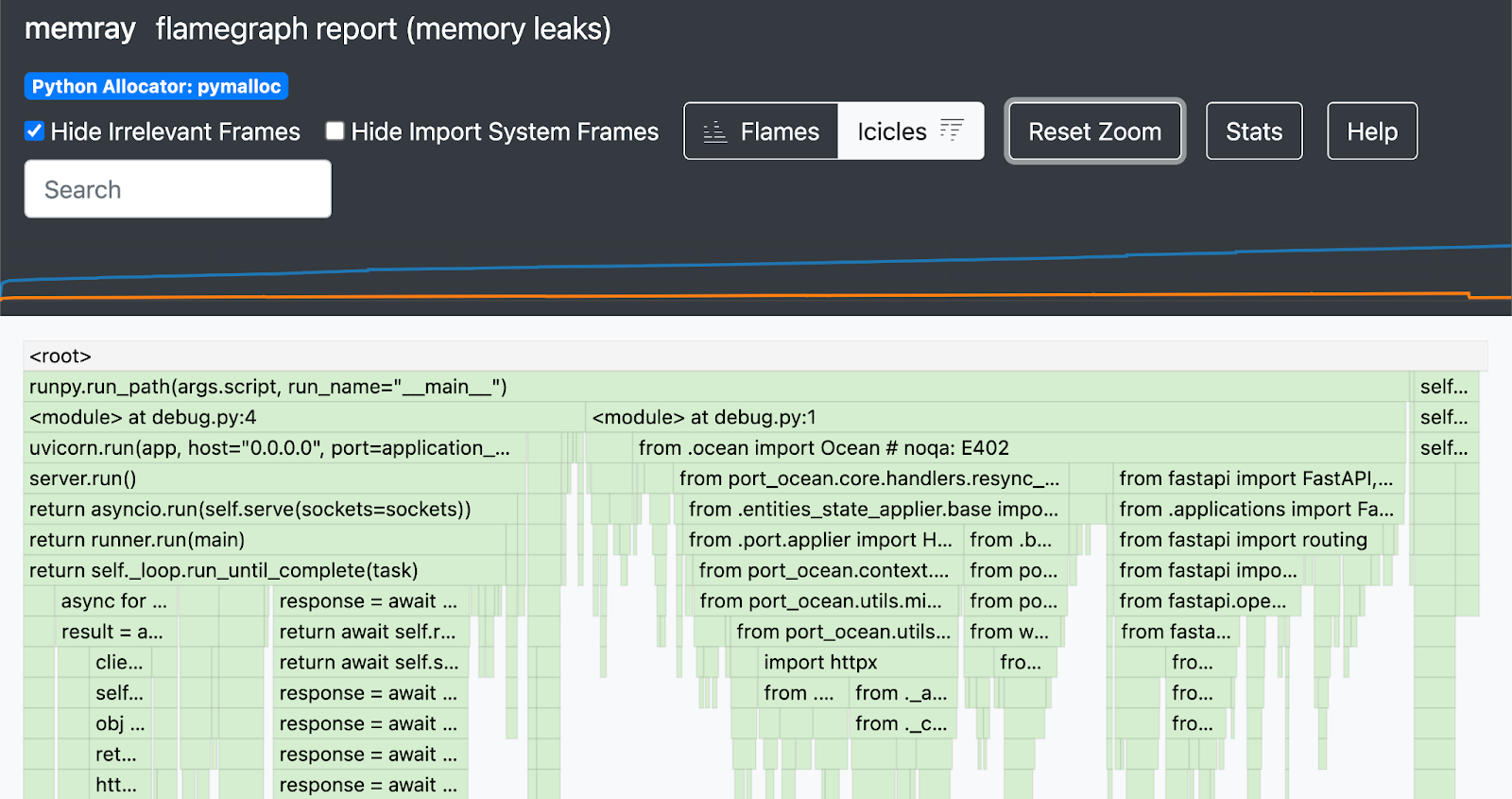
Memray’s flamegraph report
Phase 3: Isolating Code with a Binary Search Strategy
When standard profiling tools didn’t yield clear answers, we shifted our focus to a methodical strategy of isolating and eliminating code segments. This approach is akin to a binary search algorithm: we stripped down the application, testing versions with major components disabled to identify which part of the code was causing the leak.
Through this process, we ruled out multiple potential culprits: async HTTP clients, the scheduler logic, and using concurrent tasks. This strategy allowed us to systematically eliminate entire sections of the codebase until only a few components remained.
Phase 4: The Surprising Culprit — Duplicated Route Registration
The solution became apparent when we isolated the FastAPI component and noticed a peculiar behavior: registering a route caused a memory leak, even if the route was never called.
FastAPI uses a router to manage incoming API requests, such as webhooks for live events, and health checks to monitor the service’s status. In the context of the integration, live events refer to notifications about changes or updates in external systems.
For example, when a new Jira issue is created or an existing issue is updated, the integration listens for these events and processes them in real time. The issue arose because every API call—whether for a live event or a health check (called by Kubernetes)—was re-running the include_router() function, leading to the repeated addition of the same routes in memory.
The Fix: Ensuring Single Route Registration
The solution was simple: ensure that include_router() is called only once during startup. By moving the route registration out of the request-handling flow and into the application initialization, we eliminated the duplicated pointers and stabilized memory usage.
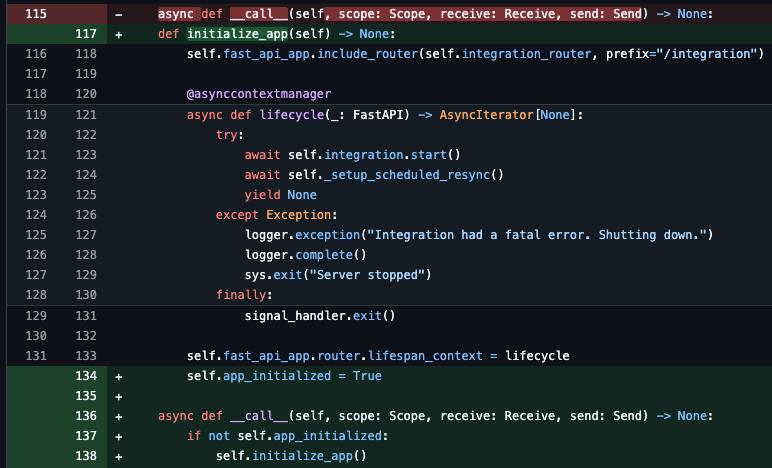
The code fix
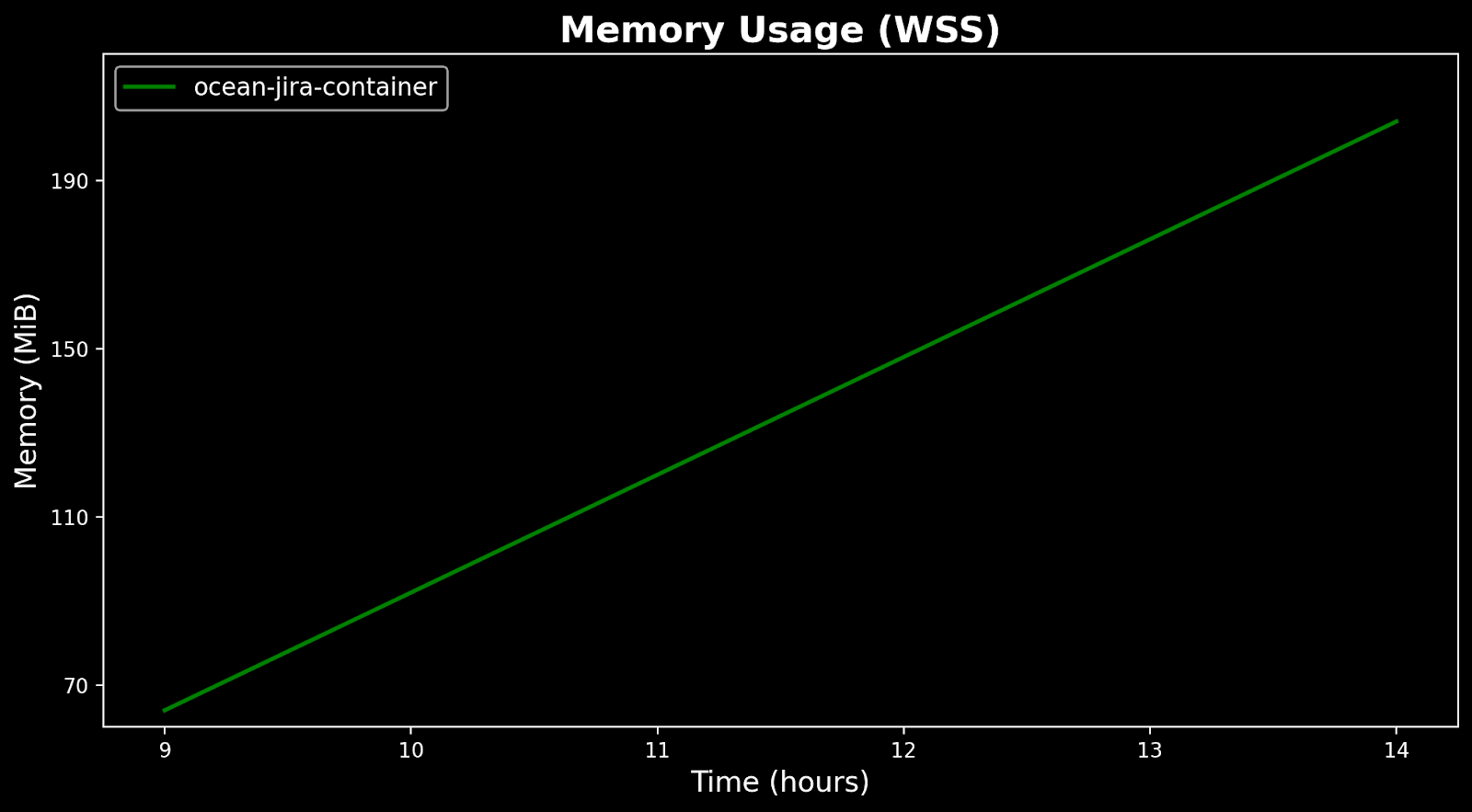
Memory usage before the fix
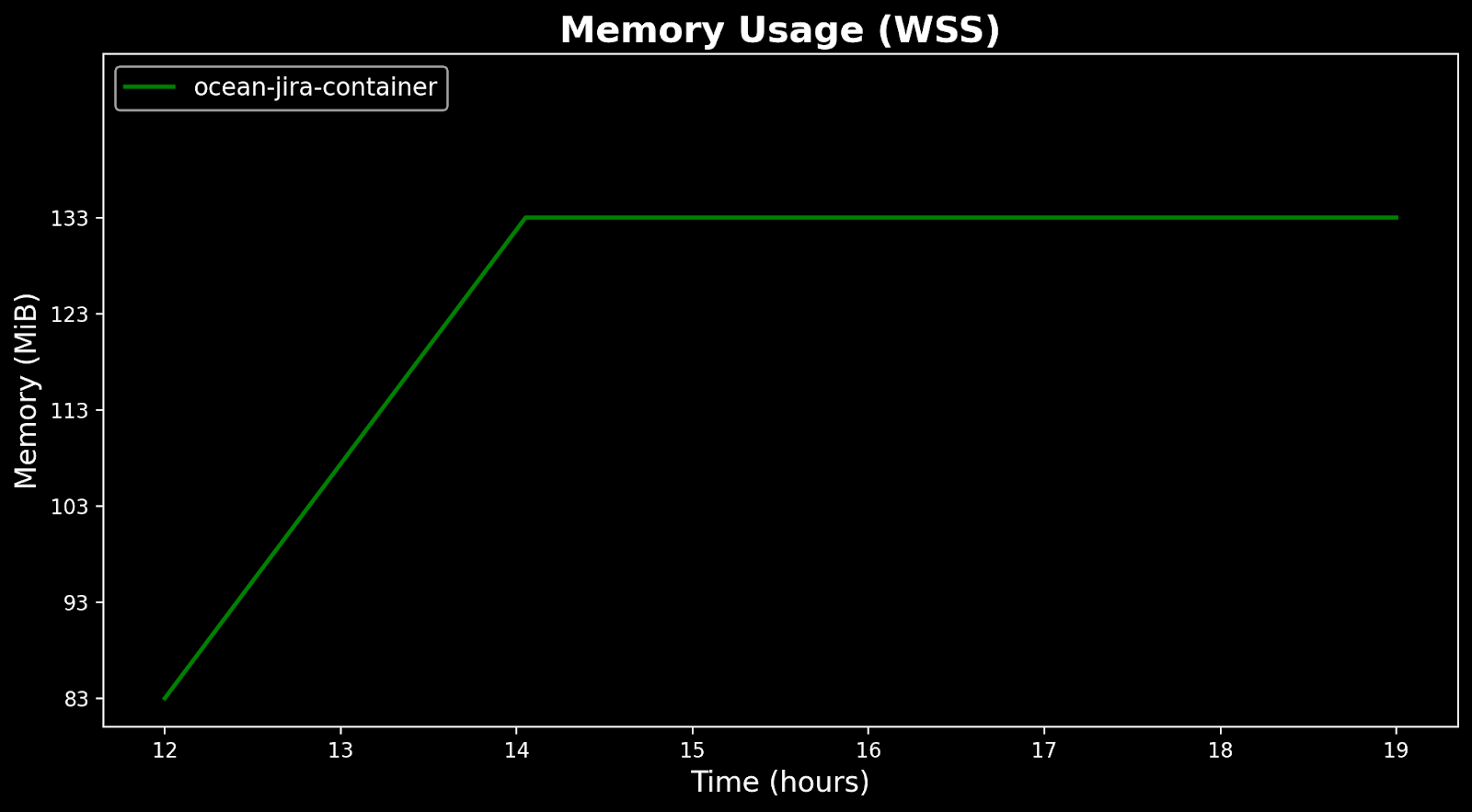
Memory usage after the fix
Lessons Learned: Debugging the Hard Way
This journey taught us several key lessons:
Environment Matters: The leak only manifested when running in a Kubernetes cluster with our Helm chart and simulating the scale of 30K Jira issues, emphasizing the importance of testing in production-like environments.
Isolation and Elimination: When standard memory profilers don’t provide answers, systematically isolating and disabling components can be a powerful debugging strategy. This method helped us quickly narrow down the problem to a specific area of the code.
Understand Framework Internals: The root cause was an unintended side effect of how FastAPI handled route registration. A deep understanding of the underlying frameworks can be crucial in diagnosing such issues.
Conclusion
Finding this memory leak was a journey of exploration and unexpected twists. We methodically ruled out potential causes one by one, even when the evidence was inconclusive. Ultimately, the issue wasn’t with async programming or memory fragmentation, but a subtle bug in how routes were registered during API calls.
The fix has been merged, and we’ve released updates to our GitHub repository. We are already seeing much-improved stability in production, and we continue to monitor memory usage closely.
We hope this deep dive into our debugging process helps others facing similar challenges. If you’re interested in contributing or learning more, check out the Ocean framework on GitHub and join the conversation!
Happy debugging! 🚀